































*姓名
*邮箱
*手机号
*验证码
*公司全称
*职位
我已阅读并同意 《用户协议》 与 《隐私政策》

Eureka平台

Eureka-知识产权类

Eureka-研发类

Eureka-生物医药类

Eureka-材料类
Eureka-通信

专利数据库AI模式

专利数据库

新药情报库

生物序列数据库

化学结构数据库

数据开放平台

2025 年 9 月
在全球化与技术飞速迭代的今天,知识产权,特别是专利,已成为衡量国家创新能力、企业核心竞争力的关键指标。从新药研发到通信标准,从人工智能算法到新材料应用,专利不仅是技术的保护屏障,更是商业博弈中的重要筹码。
传统的专利工作流程——包括检索、分析、撰写、审查和诉讼等——是典型的高门槛、知识密集型和劳动密集型任务。一位资深的专利工程师或律师,需要经过多年的学习和实践,才能精准地把握技术要点、理解法律条款、撰写出高质量的专利文件。
近年来,以大语言模型为代表的人工智能技术取得了突破性进展,其强大的自然语言理解、生成和推理能力,为变革各行各业带来了无限可能。当这股浪潮涌入专利领域时,人们不禁要问:AI能否真正理解复杂的专利文献?能否辅助专利从业者完成高难度的专业任务?AI在专利领域的应用边界在哪里?其能力水平究竟如何?
为了科学、系统地回答这些问题,一个权威、全面、专业的评测标准变得至关重要。PatentBench评测基准应运而生。PatentBench评测基准包括“十大专利基础核心能力评测”和“专利任务应用评测”两部分。它不仅仅是一个简单的测试集,它是一项全面、深度、精准地评估专利大模型及专利任务智能体的综合性评测基准。

PatentBench旨在为专利领域的AI大模型和AI 智能体提供一把精准的“度量尺”,既能检验其基础能力,又能评估其在真实世界复杂任务中的应用表现。它的出现,标志着“AI+专利”的发展从概念探索阶段,正式迈向了有标准可依、有方向可循的规模化、专业化发展新阶段。
专利工作的本质是对高度专业化文本的处理和理解。因此,一个优秀的专利大模型必须首先具备扎实的底层能力。PatentBench围绕专利领域核心的十大基础能力展开,旨在全面评估大模型在处理专利文本时的“基本功”。
专利十大基础核心能力包含哪些部分,评测的难点和要点在哪里?

1.专利问答能力
评测各类大模型能否准确回答关于特定专利文件、技术领域或专利法律法规的各种问题。问题类型覆盖事实检索型(如“某专利的申请日是哪天?”)、定义解释型(如“什么是‘新颖性宽限期’?”)和深度理解型(如“请解释该专利权利要求3的技术方案如何解决其声称的技术问题?”)。
2.专利解读能力
评测超越简单的问答,要求被评测模型深度剖析专利文献的核心——权利要求书(Claim)和说明书(Description)。该能力评测各类大模型能否准确识别专利的保护范围、提炼发明的核心技术点、梳理技术方案的实施路径。专利解读是所有后续分析的基础。错误的解读将导致“差之毫厘,谬以千里”的严重后果。此项能力是衡量模型是否具备“专业级”理解能力的关键。
3.专利翻译能力
评测评估模型在不同语言(如中、英等)之间翻译专利文献的准确性、专业性和流畅性。重点考察对技术术语、专利术语以及长难句结构的翻译是否精准。专利具有地域性,跨国专利申请和诉讼是常态。高质量的机器翻译不仅能大幅降低成本,更能加速技术信息的流转。PatentBench对翻译的评测,强调的是“信、达、雅”中的“信”与“达”,即忠实于原文且符合目标国专利语言规范。
4.专利抽取能力
评测各类大模型能否从专利文本中确地抽取出关键信息,如技术问题、技术功效等。结构化信息是进行大数据分析、专利地图绘制、技术趋势预测的前提。高效的信息抽取能力,能将海量专利文献转化为可供分析的数据资产。
5.专利考试能力
评测通过模拟各国专利代理师资格考试的真实题目,检验模型对专利法律法规、审查指南及实务知识的掌握程度。这项评测极具挑战性,它直接对标人类专家的准入门槛。如果一个模型能在此项测试中取得高分,意味着它已经内化了海量的专利法条和案例,具备了提供专业咨询的潜力。
6.专利总结能力
评测要求各类大模型为一篇长篇专利文献生成不同类型的总结。例如,为技术人员生成的“一句话技术摘要”,或为律师生成的“核心权利要求摘要”。专利文献复杂,快速获取其核心内容对于决策至关重要。智能总结能帮助用户在几秒钟内判断一篇专利的相关性(Relevance),极大地提升了信息筛选的效率。
7.专利分类能力
评测根据专利的技术内容为其分配正确的分类号。专利分类是专利检索的“导航系统”。准确的分类是确保检索查全率和查准率的基础。智能分类不仅能减轻审查员和代理人的负担,还能提高分类的一致性和准确性。
8.专利撰写能力
评测评估模型辅助专利申请文件内容的撰写能力,特别是技术背景、发明内容以及权利要求的撰写。评测重点在于生成文本的逻辑性、清晰度、合规性以及对保护范围的合理布局。专利撰写是专利工作中“含金量”最高的环节之一。AI的介入,有望将专利工程师从繁琐的格式化写作中解放出来,更专注于发明构思和保护边界的打磨,从而提升专利质量、缩短撰写周期。
9.专利多轮能力
评测在连续的对话中,大模型能否保持对复杂专利话题的上下文理解,并根据用户的追问和反馈,逐步深入、精确化或修正其回答和分析。例如,模拟用户与AI探讨一项发明的多种撰写策略。真实的专利工作场景充满了动态交互。多轮对话能力决定了AI能否成为一个真正有用的“智能助手”,而非一个只能“一问一答”的简单工具。
10.专利推理能力
专利推理能力评测是对大模型认知能力的最高阶测试。要求模型基于给定的专利A和产品B的技术特征,推理判断产品B是否可能落入专利A的保护范围;或者基于专利X和专利Y,判断两者之间是否存在引用、继承或冲突关系。具备强大推理能力的AI,能在专利有效性分析、侵权风险预警、技术路线规划等高级任务中扮演关键角色,真正实现从“信息处理”到“决策支持”的飞跃。
如果说专利基础核心能力评测是“各项体能测试”,那么专利任务应用评测就是“全能实战对抗”。专利任务智能体(Agent)是集成了多种基础能力、面向特定应用场景的复杂AI系统。
PatentBench首期通过构建专利查新、专利防侵权、专利翻译、专利说明书助手和外观防侵权五大核心应用评测的目标任务和评测维度,检验AI在模拟真实工作流中的综合表现。后期,还会快速扩展到更多的专利应用场景进行基准测试。

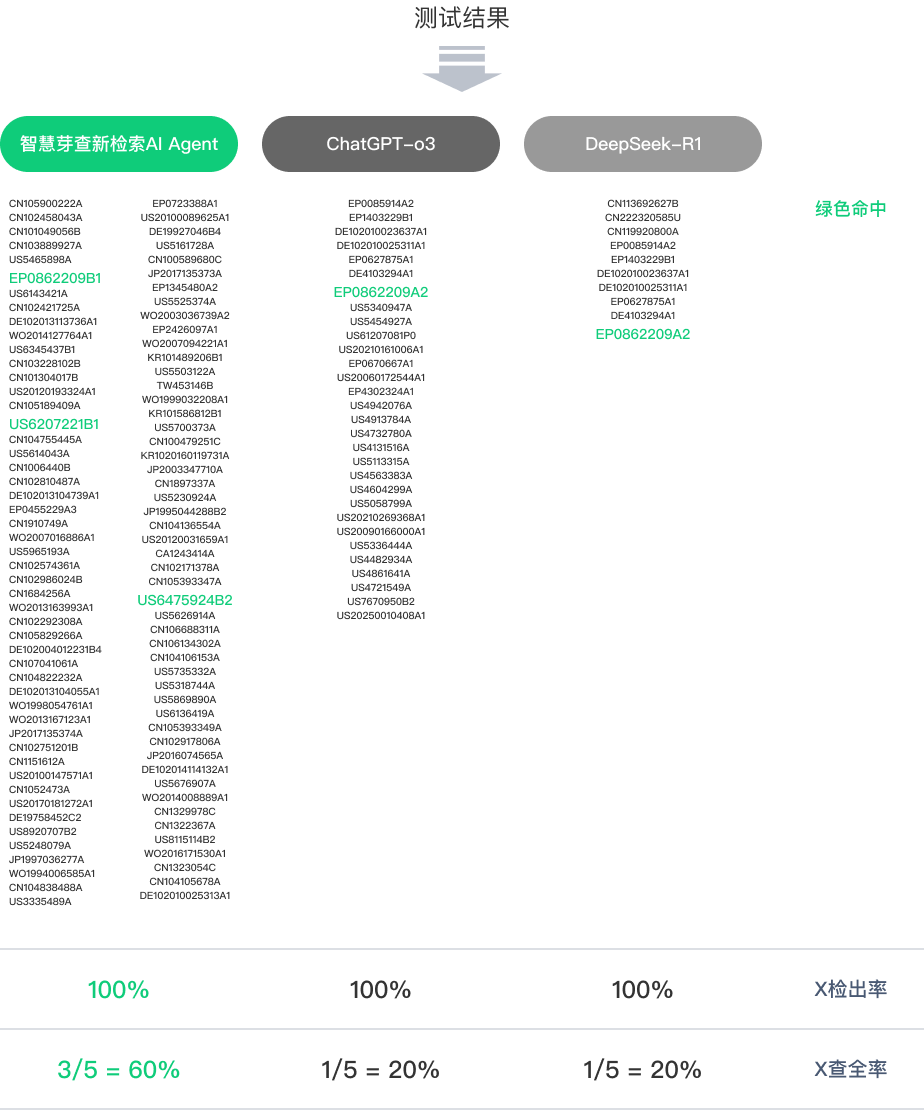
1.专利查新
目标任务:在发明人提交技术交底书后,进行专利查新(Prior Art Search),判断其是否具备新颖性和创造性,这是专利申请前最关键的一步。
评测维度:
1)专利特征拆解能力:智能体能否像专利工程师一样,将技术交底书中的发明构思,精准地拆解为一系列结构化的技术特征点。
2)专利查新能力:基于拆解出的技术特征,智能体能否构建高效的检索策略,在全球专利和非专利文献中,全面、准确地找到最相关的对比文件。
3)专利特征对比能力:将检索到的对比文件与本发明的技术特征进行逐一比对,清晰地指出哪些特征是现有技术,哪些特征构成了区别技术特征,并初步判断其新颖性和创造性。
2.专利防侵权
目标任务:企业在推出新产品前,进行自由实施分析(FTO, Freedom-to-Operate),评估该产品是否存在侵犯他人有效专利权的风险。
评测维度:
1)侵权专利召回能力:根据新产品的技术方案,智能体能否在海量专利中,最大范围地找出可能构成侵权风险的高度相关专利。这要求极高的检索查全率。
2)侵权专利分析能力:对召回的高度相关专利,智能体能否进行深入的权利要求比对(Claim Charting),即“技术特征-权利要求”一一对应分析,并给出初步判断和分析报告。
3.专利翻译
目标任务:提供满足多国专利局提交要求的、专业级的专利翻译服务。
评测维度:
1)专利翻译能力:这里的翻译能力要求更高,不仅要准确,还要适应不同国家专利审查的“口味”,例如术语使用的偏好、句式结构的规范等。
2)专利语言规范能力:智能体能否在翻译的同时,自动检查并修正译文,使其完全符合目标国专利局的格式要求和语言习惯,例如,避免使用模糊词汇、确保术语一致性、正确使用附图标记等。
4.专利说明书助手
目标任务:根据交底书和权利要求文本深度辅助生成专利说明书内容。
评测维度:
1)专利撰写能力:在接收技术交底书和权利要求后,智能体能否生成逻辑清晰、层次分明、术语准确并满足各受理局法律要求的技术手段、技术功效、实施例等说明书内容初稿。
2)专利语言规范能力:对生成的说明书初稿,进行“核稿”和“纠错”,检查是否存在错误或不合理描述(如形式错误、语法错误、一致性错误,幻觉等),确保权利要求布局合理、保护范围得当。
5.外观防侵权
目标任务:针对产品的外观设计,评估其是否侵犯他人的外观设计专利权。
评测维度:
1)外观侵权图片召回能力:此能力的核心是“以图搜图”。智能体能否基于新产品的图片或设计图,在海量的外观设计专利数据库中,检索出视觉上最相似的设计。
2)侵权图片分析能力:从“一般消费者”的视角,对比新产品与检索到的相似设计,分析两者在整体视觉效果上是否存在实质性差异,并给出侵权风险的判断依据
首先,为技术发展指明了方向。 对于AI研发者而言,PatentBench就像一张清晰的“能力地图”和“任务清单”。他们可以针对性地指导优化模型在特定能力上的表现,开发更贴合实际需求的专利智能体,避免了在通用能力上“内卷”而在专业应用上“偏科”的窘境。
其次,为用户选择提供了依据。 对于广大的专利从业者和企业而言,面对市场上琳琅满目的“AI+专利”产品,PatentBench提供了一个客观、公正的第三方评价体系。用户可以根据评测结果,选择最适合自身需求的工具,降低了试错成本,加速了AI技术的落地应用。
再次,推动整个行业标准的建立。 PatentBench的实践,将促进形成一套关于AI在专利领域应用效果的公认标准。这有助于行业的良性竞争,淘汰能力不足的伪劣产品,激励高质量、真有效的技术创新,最终提升整个专利行业的智能化水平和服务质量。
PatentBench评测基准本身也将不断演进。随着AI技术的发展和专利业务的深化,未来会对更多更全面的专利应用场景进行全面评测。



立即体验


微信咨询

了解产品 咨询报价


电话咨询
欢迎拨打电话咨询


小程序
